-
Go/Java: 금칙어 검사 함수들 벤치마크 및 향상컴퓨터/Go language 2024. 5. 2. 00:28728x90반응형
금지어 리스트를 .txt 에 저장하고 서버 메모리에 로딩했다. (10kb)
금지어를 가장 빠르게 체크하는 방법은 무엇일까 궁금해서 벤치마크를 돌려보았다.
기준: 10KB input string + 500개 금지어 리스트
1. 정규 표현식 사용
- 성능: 14,260K ns/op
- 메모리 사용: 4321B/op
- 할당 횟수: 24 allocs/op
아래처럼 첫 로딩에 regex로 패턴을 모두 컴파일하고, 인풋 string을 확인했다.
생각보다 대용량일 수록 굉장히 느리다.
func CompileBadWordsPattern() error { var pattern strings.Builder pattern.WriteString(`(`) for i, word := range badWordsList { if word == "" { continue } pattern.WriteString(regexp.QuoteMeta(word)) if i < len(badWordsList)-1 { pattern.WriteString(`|`) } } pattern.WriteString(`)`) var err error badWordRegex, err = regexp.Compile(pattern.String()) return err }2. 단순 문자열 검사 (strings.Contains)
- 성능: 1066K ns/op
- 메모리 사용: 322B/op
- 할당 횟수: 2 allocs/op
단순히 모든 금지어들 input에 있나 확인하는 방법이다.
당연히 메모리 사용량과 할당 횟수가 적다.
func CheckForBadWordsWithGo(input string) (bool, error) { for _, word := range badWordsList { if word == "" { continue } if strings.Contains(input, word) { return true, nil } } return false, nil }3. 병렬 처리 문자열 검사 (goroutines)
- 성능: 194,213K ns/op
- 메모리 사용: 51,573B/op
- 할당 횟수: 1072 allocs/op
strings.Contains이지만 각 금지어마다 goroutine을 불러서 (스레드 개념) 병렬로 처리해 보았다.
메모리 사용량이 가장 많다. (각각 고루틴이 독립적인 스택 메모리를 사용하기 때문)
func CheckForBadWordsWithGoRoutine(input string) (bool, error) { ctx, cancel := context.WithCancel(context.Background()) defer cancel() resultChan := make(chan bool) var wg sync.WaitGroup for _, word := range badWordsList { wg.Add(1) go func(w string) { defer wg.Done() select { case <-ctx.Done(): return // Early exit on context cancellation. default: if w == "" { return // Skip empty words. } if strings.Contains(input, w) { resultChan <- true cancel() // Found a bad word, signal to cancel other goroutines. } } }(word) } go func() { wg.Wait() close(resultChan) }() for result := range resultChan { if result { return true, nil } } return false, nil }위 3가지에 대한 그래프는 다음과 같다.
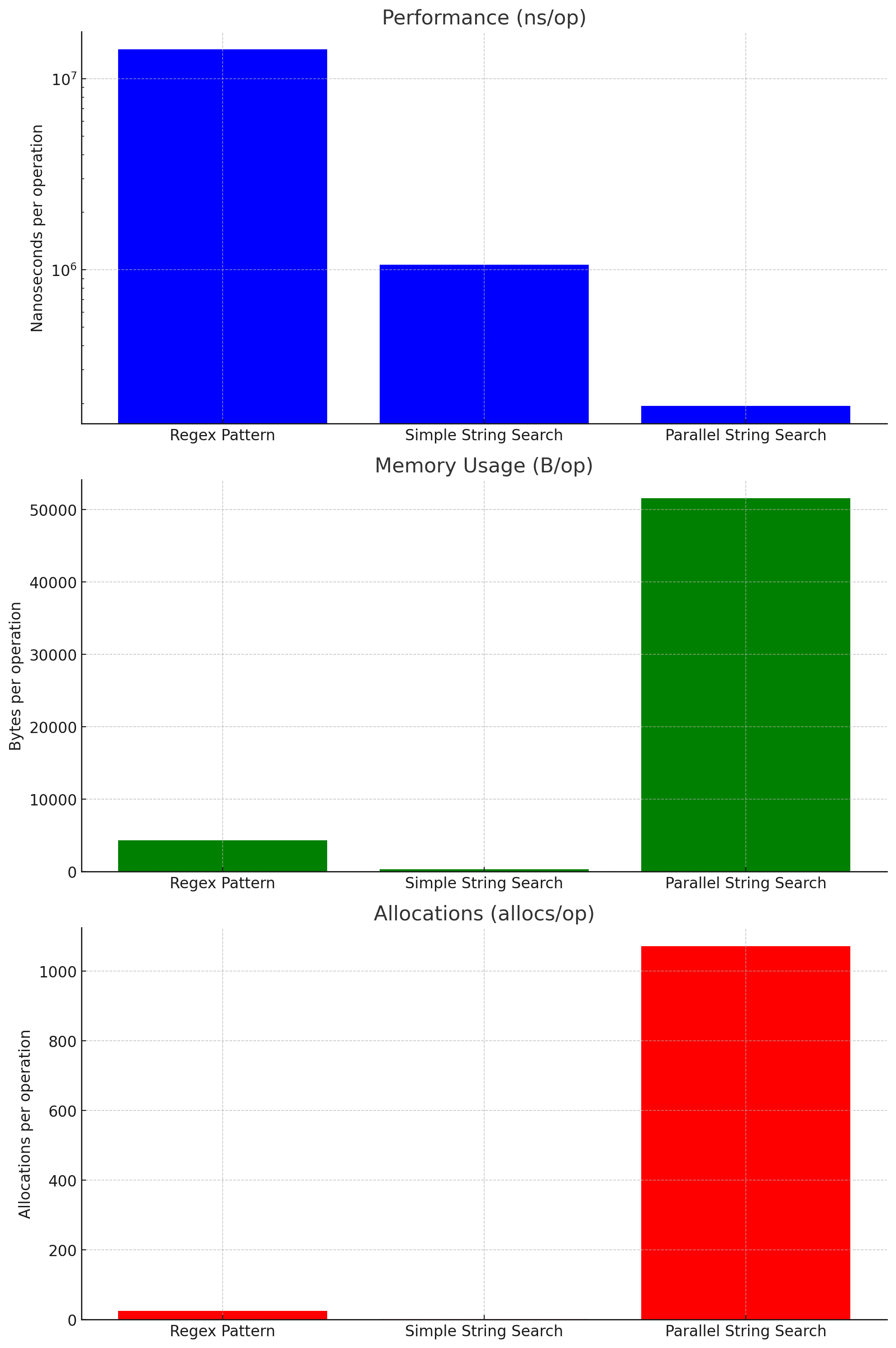
성능: 병렬 처리 방식 >> 단순 문자열 검색 > 정규 표현식 병렬 처리가 속도는 좋지만 메모리를 많이 잡아먹는다.
그렇다고 단순 문자열 검사 방식을 쓰자니, 메모리도 적게 잡고 속도가 더 빠른 방법을 찾고 싶었다.
4. 아호코라식
다중 문자열 검색 알고리즘이다. (@1975년 논문 링크)
한 번의 스캔으로 입력 문자열에서 여러 패턴을 동시에 찾게 해 줄 수 있다. (문자열 검색, 네트워크 패킷 분석 등....)
이 알고리즘은 Trie를 필요로 하고, 실패 링크를 설정해야 한다.
(모든 패턴 포함 -> Trie, 각 노드 매칭 실패 시 이동할 노드 (KMP의 부분 일치 테이블처럼) -> Failure Links)
단순하게 구현할 순 있겠지만
type node struct { children map[rune]*node output []string failure *node } func (n *node) search(text string) []string { current := n results := []string{} for _, r := range text { for current != nil && current.children[r] == nil { current = current.failure } if current == nil { current = n continue } current = current.children[r] results = append(results, current.output...) } return results }잘 구현된 라이브러리를 이용해 보고자 한다. https://pkg.go.dev/github.com/rrethy/ahocorasick
찾아보니 이중 Trie 나 LinkedList Trie 같은 자료구조로도 만들기도 하는 듯하다.
DAT
Double-Array Trie는 쉽게 들을 수 있는 자료구조는 아닌 것 같다.
간단히 정리하면, 기본 Trie는 각 노드가 자식 노드에 대한 포인터를 갖고 있어야 하고,
각 노드는 해당하는 문자를 저장하는 공간이 필요하게 된다. (즉, 공간 효율성이 떨어짐)
DAT는 2개의 배열 (Base + Check)을 사용해서 해결한다. (불필요 노드 생성 방지)
- Base 배열: 현재 노드에서 특정 자식 노드로 가기 위한 기준 값 저장
- Check 배열: 실제로 해당 인덱스가 유효한 자식인지를 확인하는 용도
// LoadBadWordsForTrie loads bad words from a file into a trie (Aho-Corasick) func LoadBadWordsForTrie(filePath string) error { file, err := os.Open(filePath) if err != nil { return err } defer file.Close() const estimatedWords = 1000 badWordsList = make([]string, 0, estimatedWords) scanner := bufio.NewScanner(file) const maxCapacity = 10 * 1024 // 10KB; buf := make([]byte, maxCapacity) scanner.Buffer(buf, maxCapacity) for scanner.Scan() { word := scanner.Text() badWordsList = append(badWordsList, word) } if err := scanner.Err(); err != nil { return err } badWordsList = append([]string{}, badWordsList...) // Compile the list of bad words into a trie matcher = ahocorasick.CompileStrings(badWordsList) return nil } // CheckForBadWordsUsingTrie checks if the input contains any bad words using Aho-Corasick trie func CheckForBadWordsUsingTrie(input string) (bool, error) { if matcher == nil { return false, os.ErrNotExist } matches := matcher.FindAllString(input) return len(matches) > 0, nil }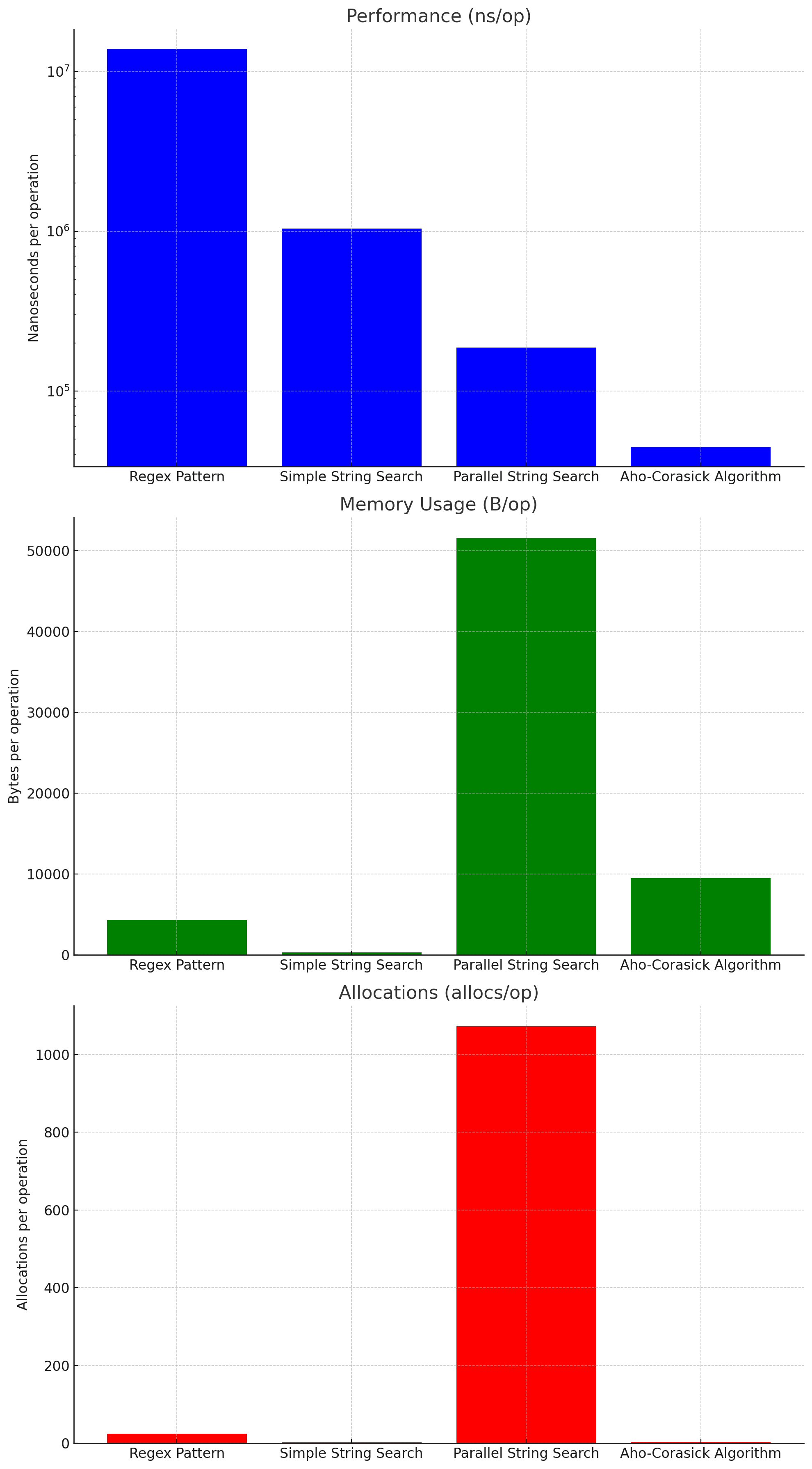
성능: DAT AC > 단순 문자열 검사 >> 멀티쓰레드 > regex 이전에 공부한 HyperLogLog 도 떠오르고 (or Bloom), Radix Trie 도 떠올랐다.
Adaptive Radix Tree라는.. 처음 보는 버전도 있고 빨라 보이지만, 부분 문자열 검색 하면서 성능을 살리긴 힘들다.
GitHub - plar/go-adaptive-radix-tree: Adaptive Radix Trees implemented in Go
Adaptive Radix Trees implemented in Go. Contribute to plar/go-adaptive-radix-tree development by creating an account on GitHub.
github.com
결과
benchtime을 다 같게 하고, 2번씩 실행한 결과다. (싱글코어/12 코어)
아호코라식 + Double-Array Trie가 메모리는 단순 strings.Contains 보다 조금 더 들겠지만,
제일 빠르다.
$ go test -benchmem -run=^$ -bench '^(BenchmarkCheckForBadWords|BenchmarkContainsWithStrings|BenchmarkContainsWithStringsConcurent|BenchmarkContainsWithAhocorasick|BenchmarkContainsWithART)$' -benchtime 1000x -count 2 -cpu 1,12 chulbong-kr/util goos: windows goarch: amd64 pkg: chulbong-kr/util cpu: Intel(R) Core(TM) i5-10600KF CPU @ 4.10GHz BenchmarkCheckForBadWords 1000 14371041 ns/op 430 B/op 2 allocs/op BenchmarkCheckForBadWords 1000 13955455 ns/op 329 B/op 2 allocs/op BenchmarkCheckForBadWords-12 1000 14697486 ns/op 432 B/op 2 allocs/op BenchmarkCheckForBadWords-12 1000 13903426 ns/op 432 B/op 2 allocs/op BenchmarkContainsWithStrings 1000 1047962 ns/op 329 B/op 2 allocs/op BenchmarkContainsWithStrings 1000 1033943 ns/op 329 B/op 2 allocs/op BenchmarkContainsWithStrings-12 1000 1039089 ns/op 329 B/op 2 allocs/op BenchmarkContainsWithStrings-12 1000 1064674 ns/op 329 B/op 2 allocs/op BenchmarkContainsWithStringsConcurent 1000 1597747 ns/op 51947 B/op 1074 allocs/op BenchmarkContainsWithStringsConcurent 1000 1592933 ns/op 51825 B/op 1074 allocs/op BenchmarkContainsWithStringsConcurent-12 1000 189257 ns/op 52017 B/op 1074 allocs/op BenchmarkContainsWithStringsConcurent-12 1000 189307 ns/op 51835 B/op 1074 allocs/op BenchmarkContainsWithAhocorasick 1000 45143 ns/op 9706 B/op 6 allocs/op BenchmarkContainsWithAhocorasick 1000 47199 ns/op 9706 B/op 6 allocs/op BenchmarkContainsWithAhocorasick-12 1000 47213 ns/op 9707 B/op 6 allocs/op BenchmarkContainsWithAhocorasick-12 1000 46609 ns/op 9706 B/op 6 allocs/op PASS ok chulbong-kr/util 65.032s15,000개 금칙어 + 10kb input
goos: windows goarch: amd64 pkg: chulbong-kr/util cpu: Intel(R) Core(TM) i5-10600KF CPU @ 4.10GHz BenchmarkCheckForBadWords-12 10 4858743430 ns/op 1602979 B/op 7288 allocs/op BenchmarkContainsWithStrings-12 10 3563700 ns/op 702328 B/op 5262 allocs/op BenchmarkContainsWithAhocorasick-12 10 1108570 ns/op 398483 B/op 3580 allocs/op PASS ok chulbong-kr/util 49.101sJava
Spring Boot 3에서 Double-Array Trie는 다음 라이브러리가 괜찮은 것 같다.
GitHub - hankcs/AhoCorasickDoubleArrayTrie: An extremely fast implementation of Aho Corasick algorithm based on Double Array Tri
An extremely fast implementation of Aho Corasick algorithm based on Double Array Trie. - hankcs/AhoCorasickDoubleArrayTrie
github.com
단어 로딩
이 Trie는 build 후 thread-safe 하다.
@PostConstruct public void init() throws IOException { trie = new AhoCorasickDoubleArrayTrie<>(); TreeMap<String, String> badWordsMap = new TreeMap<>(); try (BufferedReader reader = new BufferedReader(new InputStreamReader( Objects.requireNonNull(getClass().getResourceAsStream("/badwords.txt")), StandardCharsets.UTF_8))) { badWords = reader.lines() .filter(word -> !word.isEmpty()) .distinct().toList(); for (String word : badWords) { badWordsMap.put(word, word); } } trie.build(badWordsMap); // thread-safe after }벤치마크
1. DAT 버전
/* 20240516 (DAT) Average input text length: 1368812.2 Average duration: 225100.0 ns (0.2251 ms, 2.251E-4 s) */ @Test void benchmarkContainsProfanity() { int iterations = 10; long totalDurationNs = 0; int totalLength = 0; for (int i = 0; i < iterations; i++) { int randomLength = new Random().nextInt(1_000_000) + 1_000_000; // Random length between 1,000,000 and 2,000,000 String largeText = generateLargeRandomKoreanText(randomLength); // Generate random length text totalLength += randomLength; long startTime = System.nanoTime(); boolean containsProfanity = profanityService.containsProfanity(largeText); long endTime = System.nanoTime(); long durationNs = endTime - startTime; // Duration in nanoseconds totalDurationNs += durationNs; // Accumulate total duration double durationMs = durationNs / 1_000_000.0; // Convert to milliseconds double durationS = durationNs / 1_000_000_000.0; // Convert to seconds System.out.println("Run " + (i + 1) + ": " + randomLength + " texts - Profanity check duration: " + durationNs + " ns (" + durationMs + " ms, " + durationS + " s)"); assertTrue(containsProfanity, "Profanity check failed on large Korean text"); } double averageDurationNs = totalDurationNs / (double) iterations; double averageDurationMs = averageDurationNs / 1_000_000.0; double averageDurationS = averageDurationNs / 1_000_000_000.0; double averageLength = totalLength / (double) iterations; System.out.println("Average input text length: " + averageLength); System.out.println("Average duration: " + averageDurationNs + " ns (" + averageDurationMs + " ms, " + averageDurationS + " s)"); // Assert that the average duration is less than 10 milliseconds (10,000,000 nanoseconds) assertTrue(averageDurationNs < 10_000_000, "Average profanity check should be faster than 10ms"); }2. String.contains 버전
/* 20240516 (String.contains) Average input text length: 1592083.3 Average duration: 5.794606E7 ns (57.94606 ms, 0.05794606 s) */ @Test void benchmarkStringContains() { int iterations = 10; long totalDurationNs = 0; int totalLength = 0; List<String> badWords = profanityService.getBadWords(); for (int i = 0; i < iterations; i++) { int randomLength = new Random().nextInt(1_000_000) + 1_000_000; // Random length between 1,000,000 and 2,000,000 String largeText = generateLargeRandomKoreanText(randomLength); // Generate random length text totalLength += randomLength; long startTime = System.nanoTime(); boolean containsProfanity = false; for (String badWord : badWords) { if (largeText.contains(badWord)) { containsProfanity = true; break; } } long endTime = System.nanoTime(); long durationNs = endTime - startTime; // Duration in nanoseconds totalDurationNs += durationNs; // Accumulate total duration double durationMs = durationNs / 1_000_000.0; // Convert to milliseconds double durationS = durationNs / 1_000_000_000.0; // Convert to seconds System.out.println("Run " + (i + 1) + ": " + randomLength + " texts - String.contains check duration: " + durationNs + " ns (" + durationMs + " ms, " + durationS + " s)"); assertTrue(containsProfanity, "String.contains check failed on large Korean text"); } double averageDurationNs = totalDurationNs / (double) iterations; double averageDurationMs = averageDurationNs / 1_000_000.0; double averageDurationS = averageDurationNs / 1_000_000_000.0; double averageLength = totalLength / (double) iterations; System.out.println("Average input text length: " + averageLength); System.out.println("Average duration: " + averageDurationNs + " ns (" + averageDurationMs + " ms, " + averageDurationS + " s)"); // Assert that the average duration is less than 100 milliseconds assertTrue(averageDurationMs < 100, "Average String.contains check should be faster than 100ms"); }결과
contains으로는 비교도 안될 정도로 빠르다.
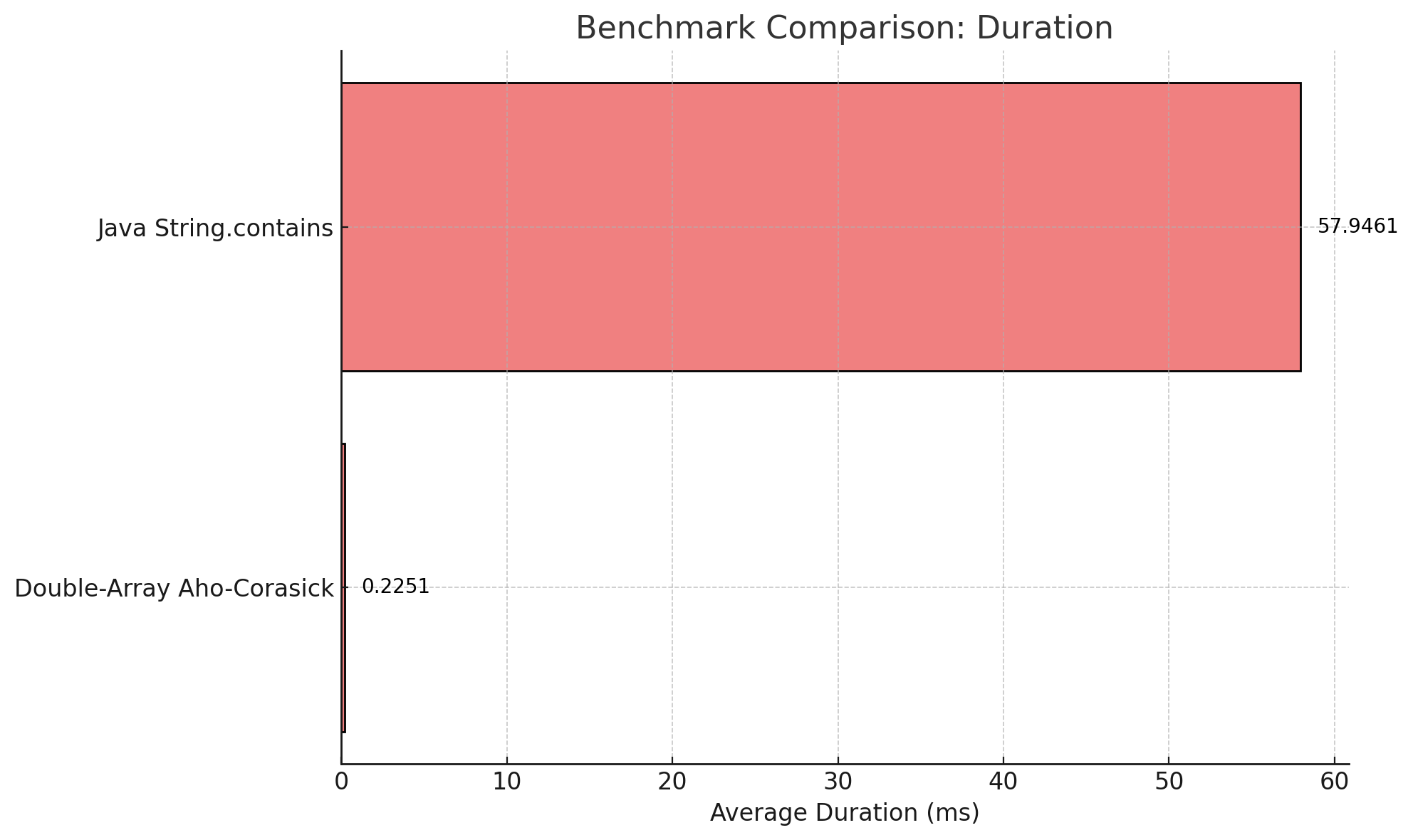
속도 비교 ms 단위, 낮을 수록 좋음 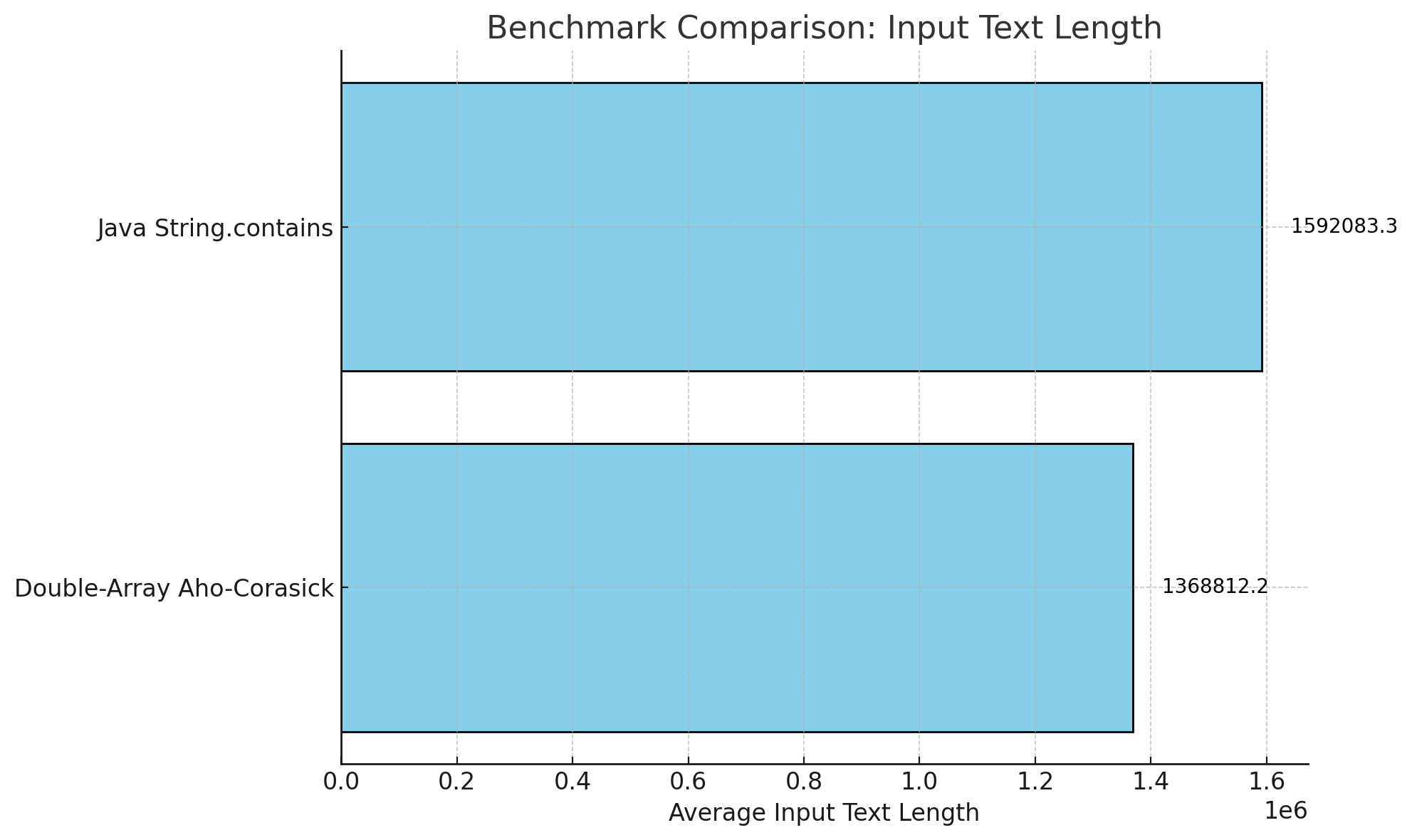
랜덤 텍스트 테스트 길이 평균 벤치마크 jmh
plugins { id 'java' ... id "me.champeau.jmh" version "0.7.2" } // https://mvnrepository.com/artifact/org.openjdk.jmh/jmh-core implementation 'org.openjdk.jmh:jmh-core:1.37' annotationProcessor 'org.openjdk.jmh:jmh-generator-annprocess:1.37' dependencies { jmh 'org.openjdk.jmh:jmh-core:1.37' jmh 'org.openjdk.jmh:jmh-generator-annprocess:1.37' jmhAnnotationProcessor 'org.openjdk.jmh:jmh-generator-annprocess:1.37' }import org.openjdk.jmh.annotations.*; import org.openjdk.jmh.infra.Blackhole; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.SpringApplication; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.context.ConfigurableApplicationContext; import org.springframework.context.annotation.AnnotationConfigApplicationContext; import java.util.List; import java.util.Random; import java.util.concurrent.TimeUnit; @SpringBootTest(classes = Application.class) @State(Scope.Benchmark) public class ProfanityServiceBenchmark2Test { @Autowired private ProfanityService profanityService; private ConfigurableApplicationContext context; @Setup(Level.Trial) public void setUp() throws Exception { context = SpringApplication.run(Application.class); profanityService = context.getBean(ProfanityService.class); profanityService.init(); } @TearDown(Level.Trial) public void tearDown() throws Exception { context.close(); } @Benchmark @BenchmarkMode(Mode.AverageTime) @OutputTimeUnit(TimeUnit.NANOSECONDS) @Warmup(iterations = 2, time = 3, timeUnit = TimeUnit.SECONDS) @Measurement(iterations = 10, time = 5, timeUnit = TimeUnit.SECONDS) public void benchmarkContainsProfanity(Blackhole blackhole) { int randomLength = new Random().nextInt(1_000_000) + 1_000_000; // Random length between 1,000,000 and 2,000,000 String largeText = generateLargeRandomKoreanText(randomLength); // Generate random length text long startTime = System.nanoTime(); boolean containsProfanity = profanityService.containsProfanity(largeText); long endTime = System.nanoTime(); blackhole.consume(containsProfanity); blackhole.consume(endTime - startTime); } @Benchmark @BenchmarkMode(Mode.AverageTime) @OutputTimeUnit(TimeUnit.NANOSECONDS) @Warmup(iterations = 2, time = 3, timeUnit = TimeUnit.SECONDS) @Measurement(iterations = 10, time = 5, timeUnit = TimeUnit.SECONDS) public void benchmarkStringContains(Blackhole blackhole) { List<String> badWords = profanityService.getBadWords(); int randomLength = new Random().nextInt(1_000_000) + 1_000_000; // Random length between 1,000,000 and 2,000,000 String largeText = generateLargeRandomKoreanText(randomLength); // Generate random length text long startTime = System.nanoTime(); boolean containsProfanity = false; for (String badWord : badWords) { if (largeText.contains(badWord)) { containsProfanity = true; break; } } long endTime = System.nanoTime(); blackhole.consume(containsProfanity); blackhole.consume(endTime - startTime); } private String generateLargeRandomKoreanText(int length) { Random random = new Random(); StringBuilder sb = new StringBuilder(length); String badWord = "시발"; // Korean bad word for testing int insertPosition = random.nextInt(length - badWord.length()); for (int i = 0; i < length; i++) { if (i == insertPosition) { sb.append(badWord); i += badWord.length() - 1; } else { char c = (char) (random.nextInt(0xD7A3 - 0xAC00 + 1) + 0xAC00); // Random Korean character sb.append(c); } } return sb.toString(); } public static void main(String[] args) throws Exception { org.openjdk.jmh.Main.main(args); } }DAT 가 약 3.39배 정도 빠른 것을 볼 수 있었다. (45.58 ms / 13.44 ms)
Benchmark Mode Cnt Score Error Units ProfanityServiceBenchmark2Test.benchmarkContainsProfanity avgt 50 13436583.455 ± 232337.249 ns/op ProfanityServiceBenchmark2Test.benchmarkStringContains avgt 50 45580378.901 ± 1271098.363 ns/op728x90'컴퓨터 > Go language' 카테고리의 다른 글
Go: Bleve 인덱싱 한국어 주소 검색 서버 만들기 (Apache Lucene-like) (0) 2024.06.02 Go: math/rand/v2 Lemire's algorithm 알고리즘 (0) 2024.04.18 Go: 카카오맵 API 정적 지도 이미지에 여러 마커들 추가하기 (0) 2024.04.11