-
Python Kafka: Avro 사용하기컴퓨터/Kafka 2020. 12. 23. 17:40728x90반응형
Apache Avro
Welcome to Apache Avro!
Welcome to Apache Avro! Apache Avro™ is a data serialization system. To learn more about Avro, please read the current documenta
avro.apache.org
1. AVRO란
Apache Kafka는 기본적으로 데이터를 binary형식으로 받아서, binary로 보낸다.
(010100001..., 카프카 자체는 데이터를 확인하지 않는다. [0% CPU usage, zero copy])
그렇기 때문에 만약 아래와 같은 상황이라면
- Producer가 잘못된 데이터를 보낼 때
- field 이름이 변경됐을 때
- 데이터 포맷 형식을 바꿔버릴 때
- 등등
당연히, Consumer는 작동을 못하게 된다.
그래서 데이터 자체가 자신을 설명할 수 있어야 하고,
Consumer를 break하지 않고 데이터를 변경될 수 있게 만들어야 한다.
그래서 schema(대략적인 계획이나 도식) 방식으로 avro가 나오게 됐다.
(JSON 형식을 사용함)
(Scheme를 사용할 때 프로그램 작동 방식)
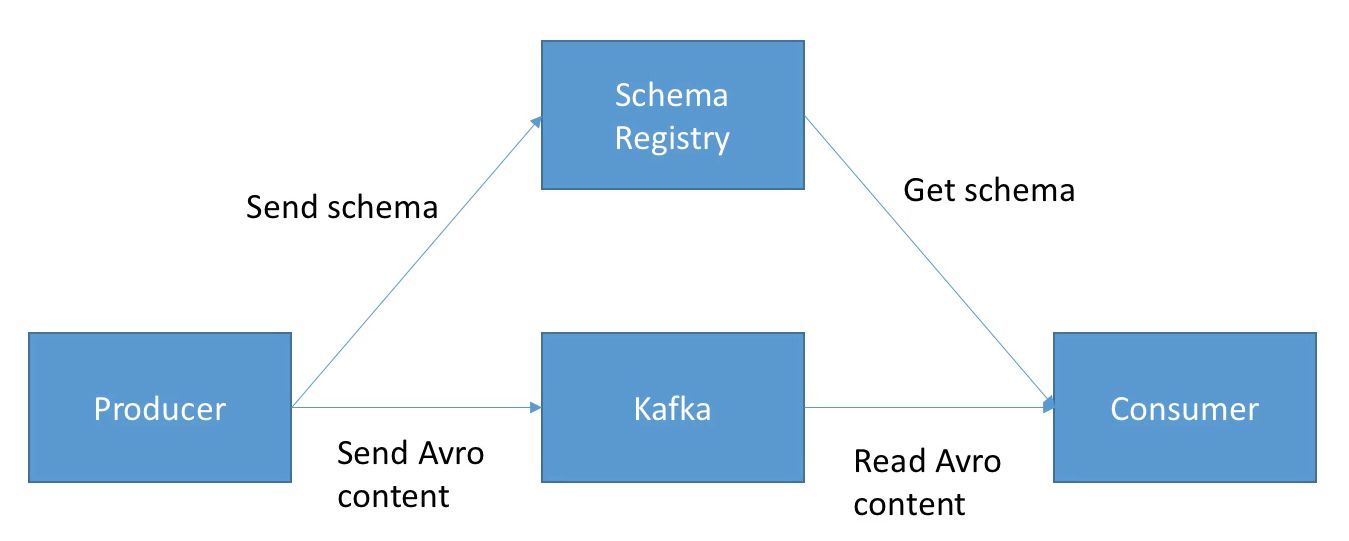
@udemy Stephane Maarek 2. Python 사용법
Python으로 avro를 사용할 때 크게 다음 3가지를 선택할 수 있다.
1. avro by Apache
2. fastavro (C언어로 작성한 avro)
3. confluent avro (fastavro 기반 HTTPS 통신 schema)
당연히 python보단 C언어로 작성된 버전이 빠르기 때문에, 이 글에선 fastavro로 예제를 만들 것이다.
설치
pip install fastavro스키마 예제
schema는 avsc로 파일로 저장된 json이나 dictionary로 바로 파싱 할 수 있다.
(아래는 dictionary로 schema 파싱)
from fastavro import parse_schema schema = { # avsc "namespace": "ajou.parser", "name": "Notice", # namespace.name으로 변경된다. "doc": "A notice parser", "type": "record", "fields": [ {"name": "id", "type": "int"}, {"name": "title", "type": "string"}, {"name": "date", "type": "string"}, {"name": "link", "type": "string"}, {"name": "writer", "type": "string"}, ], } """ 아래 message를 보내는 것이랑 같다. message = { "id": 10000, "title": "[FastAVRO] 테스트 공지 제목", "date": "20.12.23", "link": "https://somelink", "writer": "alfex4936", } """ parsed_schema = parse_schema(schema) # avro schema로 변환avro 파일 write 하기
# 'records' can be an iterable (including generator) records = [ { "id": 10005, "title": "공지 1", "date": "2020-12-01", "link": "https://link=10005", "writer": "CSW", }, { "id": 10006, "title": "공지 2", "date": "2020-12-02", "link": "https://link=10006", "writer": "CSW", }, { "id": 10007, "title": "공지 3", "date": "2020-12-04", "link": "https://link=10007", "writer": "CSW", }, ] BASE_DIR = os.path.dirname(os.path.abspath(__file__)) AVRO_PATH = os.path.join(BASE_DIR, "test.avro") # 현재 폴더에 test.avro 저장 # Writing with open(AVRO_PATH, "wb") as out: writer(out, parsed_schema, records)avro 파일 read 하기
# Reading with open(AVRO_PATH, "rb") as fo: for record in reader(fo): print(record) assert isinstance(record["id"], int) """ record는 dictionary로 출력 {'id': 10005, 'title': '공지 1', 'date': '2020-12-01', 'link': 'https://link=10005', 'writer': 'CSW'} {'id': 10006, 'title': '공지 2', 'date': '2020-12-02', 'link': 'https://link=10006', 'writer': 'CSW'} {'id': 10007, 'title': '공지 3', 'date': '2020-12-04', 'link': 'https://link=10007', 'writer': 'CSW'} """Producer, Consumer 예제
Producer로 하나의 avro record를 Consumer로 보내는 방법은 아래와 같다.
from io import BytesIO from fastavro import parse_schema, schemaless_reader, writer # 아래와 같은 데이터가 있을 때 message = { "id": 10000, "title": "[FastAVRO] 테스트 공지 제목", "date": "20.12.23", "link": "https://somelink", "writer": "alfex4936", } # Producer part producer_rb = BytesIO() # 바이트로 변환 schemaless_writer(producer_rb, parsed_schema, message) # 1개의 data write produced_data = producer_rb.getvalue() producer.produce(produced_data) # Producer ... 각각 다른 py # Consumer part # SIGINT can't be handled when polling, limit timeout to 1 second. msg = c.poll(1.0) # consume data from producer message = msg.value() consumer_rb = BytesIO(message) decoded = schemaless_reader(consumer_rb, parsed_schema) # 1개의 data read assert decoded == { "id": 10000, "title": "[FastAVRO] test title", "date": "20.12.23", "link": "https://somelink", "writer": "alfex4936", }728x90'컴퓨터 > Kafka' 카테고리의 다른 글
Python Kafka: Cloud Karafka 이용하기 (0) 2020.12.24 Apache Kafka: local을 위한 명령어 인터페이스 (CLI) (0) 2020.12.18 Hyper-V 가상 linux/ubuntu, Kafka 서버 외부에서 접속하기 (0) 2020.12.17